As a follow up to my tests with the Introspector from the Java API, I did some more testing with the following Java Bean to Java Bean mappers:
Furthermore I used my own implementation and an implementation that’s hardcoded by hand.
The Eclipse project with the sample code for this post can be downloaded as tar.gz or zip or can be viewed online here.
Testing
The performance test creates two beans: one is filled and the other gets filled; this is done over and over again in a big for loop. I coded a by hand implementation as a reference to check whether the process of creating all these new objects is slow. This implementation copies the properties from one bean to the other like so:
bean2.setFoo(bean1.getFoo()); bean2.setBar(bean1.getBar()); bean2.setTee(bean1.getTee()); |
All the other frameworks had to do the same thing. Have a look at the results (note that I set the y-axis to logarithmic scale):
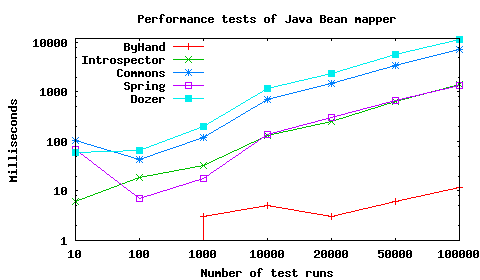
Obviously there’s no problem with all the created objects: the by hand implementation just consists of the created objects and some method calls to copy the properties. This seems to be pretty fast compared to the other solutions.
Let us have a look at a comparison between the by hand implementation and the frameworks when they have to fill 100k objects:
| by Hand | Introspector | Commons | Spring | Dozer | |
|---|---|---|---|---|---|
| by Hand | 1 | 120 | 610 | 110 | 970 |
For example: the by hand implementation beats Dozer by a factor of 970, i.e. it’s 970 times faster.
Conclusion
The results can be explained with the different richness of features. My Introspector and the implementation from the Springframework have very few features and are pretty fast. The Commons BeanUtils implementation has a lot of features (e.g. all this DynaBean stuff). And finally Dozer: I haven’t looked at the code yet, but it seems to be very powerful.
So once more it’s a trade-off between speed and features. Obviously you can’t have both so decide which one your application needs.
thanks for user test.
I downloaded the sources. There are some issues when measuring the performance this way (PerformanceComparison class):
Method.setAccessible(true).So, the results give some hint about what’s going on, but I recommend that one should not rely on those figures.
Hi AA,
you’re totally right that the tests aren’t that accurate. All I wanted to do was to give some hint about the performance for the various implementations – as you suggest we shouldn’t rely on these figures but test the performance in real applications instead for better results.
Just the right info. I needed to get by. Thanks.
Pingback: benelog's me2DAY
It’s worth mentioning that this article seems to have been plagiarized in it’s entirety. If you’re curious, the other article (matching word for word) can be found at http://knol.google.com/k/kamal-kumar/java-bean-mapper-performance-tests/1ewa3fwfhc8oq/9#
I modified the test to include Orika, and here is the results: http://bit.ly/ogkdsv
Orika is a Java Bean mapper that recursively copies (among other capabilities) data from one object to another. It performs close to by hand.
Hi Smel,
thanks for the update on the tests I did. I definitely have to checkout Orika now and thank you for the hint since I know some colleagues who will be interested as well 😉
Hi Smel,
Can I have reference link regarding orika. I am using dozzer in my projects regularly. So if you can give. i would be able to think over orika.
Hi Anand,
I found the project hosted at Google over here, you might want to check it out there.
Thanks Christian. Yes, the project is hosted at Google.
Thanks Christian.
Pingback: Technical Diary » Blog Archive » links for 2011-07-21
there is a new java bean mapping framework, JMapper at:
http://code.google.com/p/jmapper-framework/
The performance is equivalent to static code and it is ease to use.
It has important features like 1 to N and N to 1 relationships, try it.
Hi, Smel:
Does orika has capacity that convert map to javabean?
Hi Samuel,
please check out the user guide of Orika to find out more about this; it is possible to work with Collections in general.
Hi Smel,
Can you include JMapper in your performance comparison?
I’ve put JMapper and Orika to test and run them on my computer.
(last column is JMapper, next one is Orika)
Hi bartek,
thanks for the comparison and posting it here. Much appreciated!
Pingback: Un poco de Herramientas de Mapeo de Beans en Java | Un poco de Java