Lately, I wrote a small tool that analyzes letter frequencies of arbitrary text files. So I decided to download all RFC‘s and give the tool a try. I was wondering whether the relative frequencies of letters in the RFC’s would match those shown on Wikipedia or other websites.
Results
I ran a case insensitive analysis on 2833 RFC’s and related text documents from here; all in all 169 MB. This took quite some time but once it was done I had these results, sorted by:
I didn’t thought that I might come up with nice results so easily.
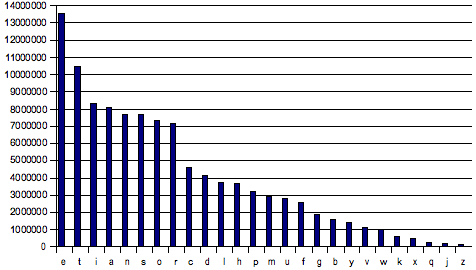
The most frequently used characters make up the word etiansor here.
Conclusion
If I seriously wanted to analyze the letter frequencies of a text corpus I would implement some sort of filtering. But without that I got reasonable results too.